I think this is how to crawl the history of a git repository
This blog post is a direct application of Cunningham’s Law: which is that “the best way to get the right answer on the Internet is not to ask a question, it’s to post the wrong answer”. With the other core developers of the Axelrod library we’re writing a paper and I wanted to see the evolution of a particular property of the library through the 2000+ commits (mainly to include a nice graph in the paper). This post will detail how I’ve cycled through all the commits and recorded the particular property I’m interested in. EDIT: thanks to Mario for the comments: see the edits in bold to see the what I didn’t quite get right.
The Axelrod library is a collaborative project that allows anyone to submit strategies for the iterated prisoner’s dilemma via pull request (read more about this here: axelrod.readthedocs.org/en/latest/). When the library was first put on github it had 6 strategies, it currently has
- This figure can be obtained by simply running:
>>> import axelrod
>>> len(axelrod.strategies)
118The goal of this post is to obtain the plot below:

EDIT: here is the correct plot:

Here is how I’ve managed that:
- Write a script that imports the library and throws the required data in to a file.
- Write another script that goes through the commits and runs the previous script.
So first of all here’s the script that gets the number of strategies:
import axelrod
from sys import argv
try:
if type(len(axelrod.strategies)) is int:
print argv[1], len(axelrod.strategies), argv[2]
except:
passThe (very loose) error handling is because any given commit might or might not be able to run at all (for a number of reasons). The command line arguments are so that my second script can pass info about the commits (date and hash).
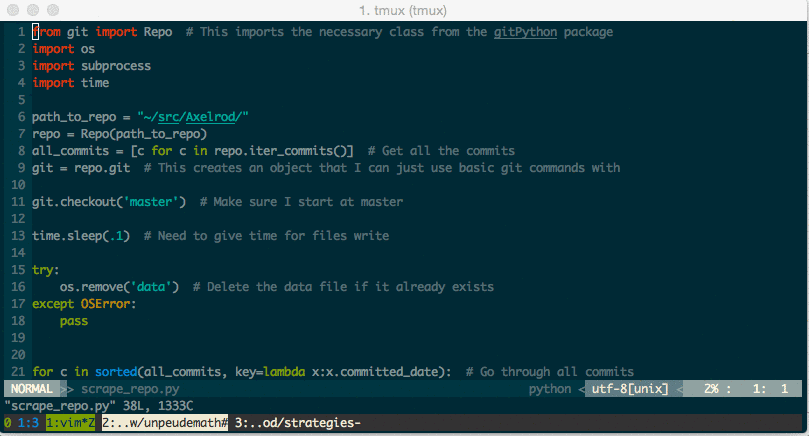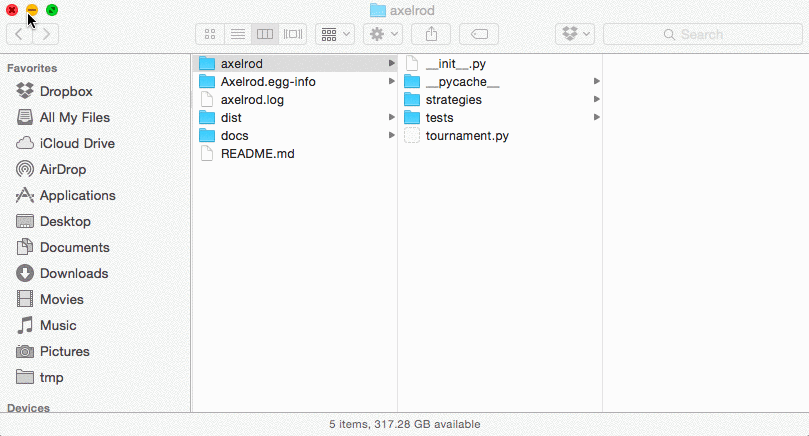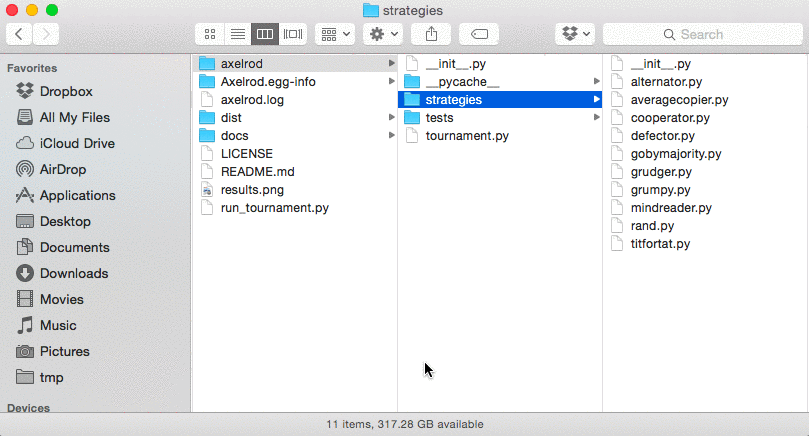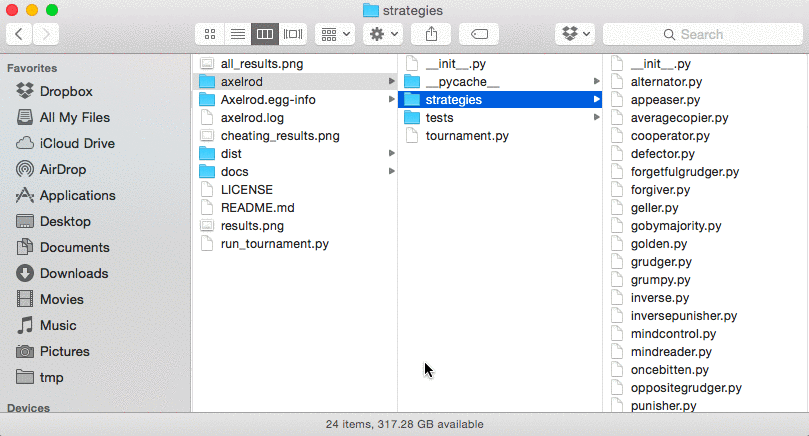
Here is the script that walks the github repository:
from git import Repo # This imports the necessary class from the gitPython package
import os
import subprocess
import time
path_to_repo = "~/src/Axelrod/"
repo = Repo(path_to_repo)
all_commits = [c for c in repo.iter_commits()] # Get all the commits
git = repo.git # This creates an object that I can just use basic git commands with
git.checkout('master') # Make sure I start at master
time.sleep(10) # Need to give time for files write
try:
os.remove('data') # Delete the data file if it already exists
except OSError:
pass
for c in sorted(all_commits, key=lambda x:x.committed_date): # Go through all commits
for rubbish in [".DS_Store",
"axelrod/.DS_Store",
"axelrod/tests/.DS_Store",
"axelrod/strategies/.DS_Store"]: # Having to delete some files that were not in gitignore at the time of the commit
try:
os.remove(path_to_repo + rubbish)
except OSError:
pass
git.checkout(c) # Checkout the commit
time.sleep(10) # Need to let files write
f = open('data', "a")
subprocess.call(['python2', 'number_of_strategies.py', str(c.committed_date), c.hexsha], stdout=f) # Call the other script and output to the `data` file
f.close()
git.checkout('master') # Go back to HEAD of masterNow, I am not actually sure if I need the 10 seconds of sleep in there but it seems to make things a little more reliable (this is where I’m hoping some knowledgeable kind soul will point out something isn’t quite right).
Here is an animated gif of the library as the script checks through the commits (I used a sleep of 0.1 second here, and cut if off at the beginning):
(You can find a video version of the above at the record.it site.)
The data set from above looks like this:
...
1424259748 6 5774fec6b3029b60c6b1bf4cb5d8bfb5323a1ad3
1424259799 6 35db17958a93e66cc09a7e7b865127b8d20acd85
1424261483 6 79c03291a1f0211925755962411d28c932150aaa
1424264425 7 f4be6bcbe9e122eb036a141f48f5acbf03b9290c
1424264540 7 6f28c9f8653e39b496c872351bce5a420e474c17
1424264950 7 456d9d25dbc44e29dde6b39455d10314824479bb
1424264958 7 0c01b14b5c3180d9e4016b09e532410cafd53992
1424265660 7 3eeec928cb7261af797044ac3bde1b26e11a7897
1424266926 7 cf506116005acd5a450894ca67eb0b670d5fd597
1424268080 8 87aa895089cdb105471280a0c374623ee7f6c9ba
1424268969 7 d0c36795fd6a69f9a1558b0b1e738d7633eb1b8e
1424270889 8 d487a97c9327235c4c334b23684583a116cc407a
1424272151 8 e9cd655661d3cef0a6df20cc509ae5ac2431f896
...That’s all great and then the plot above can be drawn straightforwardly. The thing is: I’m not convinced it’s worked as I had hoped. Indeed: c7dc2d22ff2e300098cd9b29cd03080e01d64879 took place on the 18th of June and added 3 strategies but it’s not in the data set (or indeed in the plot).
Also, for some reason the data set gets these lines at some point (here be gremlins…) ?????:
...
<class 'axelrod.strategies.alternator.Alternator'>
<class 'axelrod.strategies.titfortat.AntiTitForTat'>
<class 'axelrod.strategies.titfortat.Bully'>
<class 'axelrod.strategies.cooperator.Cooperator'>
<class 'axelrod.strategies.cycler.CyclerCCCCCD'>
<class 'axelrod.strategies.cycler.CyclerCCCD'>
<class 'axelrod.strategies.cycler.CyclerCCD'>
<class 'axelrod.strategies.defector.Defector'>
<class 'axelrod.strategies.gobymajority.GoByMajority'>
<class 'axelrod.strategies.titfortat.SuspiciousTitForTat'>
<class 'axelrod.strategies.titfortat.TitForTat'>
<class 'axelrod.strategies.memoryone.WinStayLoseShift'>
...What’s more confusing is that it’s not completely wrong because that does overall look ‘ok’ (correct number of strategies at the beginning, end and various commits are right there). So does anyone know why the above doesn’t work properly?
I’m really hoping this xkcd comic kicks in and someone tells me what’s wrong with what I’ve done:

EDIT: Big thanks to Mario Wenzel below in the comments for figuring out everythig that wasn’t quite right.
Here’s the script to count the strategies (writing to file instead of piping and also with correct error catching to deal with changes within the library):
from sys import argv
import csv
try:
import axelrod
strategies = []
try:
if type(axelrod.strategies) is list:
strategies += axelrod.strategies
except (AttributeError, TypeError):
pass
try:
if type(axelrod.ordinary_strategies) is list:
strategies += axelrod.ordinary_strategies
except (AttributeError, TypeError):
pass
try:
if type(axelrod.basic_strategies) is list:
strategies += axelrod.basic_strategies
except (AttributeError, TypeError):
pass
try:
if type(axelrod.cheating_strategies) is list:
strategies += axelrod.cheating_strategies
except (AttributeError, TypeError):
pass
count = len(set(strategies))
f = open('data', 'a')
csvwrtr = csv.writer(f)
csvwrtr.writerow([argv[1], count, argv[2]])
f.close()
except:
passHere is the modified script to roll through the commits (basically the same
as before but it calls the other script with the -B flag (to avoid
importing compiled files) and also without the need to sleep:
from git import Repo
import axelrod
import os
import subprocess
import time
import csv
path_to_repo = "~/src/Axelrod"
repo = Repo(path_to_repo)
all_commits = [c for c in repo.iter_commits()]
git = repo.git
number_of_strategies = []
dates = []
git.checkout('master')
try:
os.remove('data')
except OSError:
pass
for c in sorted(all_commits, key=lambda x:x.committed_date):
for rubbish in [".DS_Store",
"axelrod/.DS_Store",
"axelrod/tests/.DS_Store",
"axelrod/strategies/.DS_Store"]: # Having to delete some files that were not in gitignore at the time of the commit
try:
os.remove(path_to_repo + rubbish)
except OSError:
pass
git.checkout(c)
try:
subprocess.call(['python2', '-B', 'number_of_strategies.py', str(c.committed_date), c.hexsha])
dates.append(c.committed_date)
except ImportError:
pass
git.checkout('master')It looks like you should delete all pyc files from the repository in
question and run the second script with the -B tag.
Thanks again Mario!